Case Study
Direktmarketing Optimierung
Noch höhere Abschlussquoten erzielen, mit Response Prognosen für Kampagnen.
Das richtige Angebot an die richtigen Kunden zu kommunizieren, sei es per E-Mail, Telefon oder auch per Post, ist ein entscheidender Erfolgsfaktor von Direktmarketing Kampagnen. Vor einer Kampagne zu wissen, welche Kunden angesprochen werden sollen, erspart Streuverluste und bringt höhere Abschlussraten.
Während Dummy Modelle nur Zufallsergebnisse liefern, wird mit dem Einsatz von Künstlichen Neuronalen Netzwerken ein deutlich zuverlässigerer Wert erzielt.
Personalisierung treibt Abschlussquoten nach oben.
Während Recommender Systeme personalisierte Vorschläge on Demand (beim Websitebesuch) oder für alle Kunden bereitstellen, werden für Direkt-Marketing-Kampagnen bestimmte Kundensegmente ausgewählt, die ein bestimmtes Angebot erhalten sollen. Mit Predictive Analytics ist es möglich, für jeden einzelnen Lead eine Abschlusswahrscheinlichkeit zu prognostizieren.
Die richtigen Kunden auswählen.
Anhand eines offenen Datensatzes einer Portugiesischen Bank kann der Data Science Prozess demonstriert werden. (S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems (2014))
Es handelt sich um 41.188 Datensätze einer Tele-Marketing Kampagne. Den angesprochenen Kunden wird vorgeschlagen, eine Termineinlage zu tätigen. In den Datensätzen sind verschiedene Variablen enthalten, wie Alter, Geschlecht, Job, Familienstatus, Ausbildung, Info über bisherige Kredite, die Anzahl und der Zeitpunkt der bisherigen Kontakte sowie exogene Faktoren wie der 3-Monats-Euribor, die monatlichen Beschäftigungszahlen oder der Consumer Price Index.
Die Zielvariable ‚y‘ nimmt die Werte 1 (Kunde hat die Termineinlage getätigt) und 0 (nicht getätigt) an.
Unser Vorgehen:
Um zu evaluieren, wie gut verschiedene Algorithmen auf diesem Datensatz performen, unterteilen wir diesen in 2 Teile, den Trainings-Datensatz (80% der Daten) und den Test-Datensatz (20% der Teile). Kategorischen Daten wie Geschelcht, Beruf und Ausbildung werden mittels „One hot Encoding“ in 0 und 1 um (z.B. wird die Spalte Marital mit 4 Werten in 4 Spalten 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown' mit jeweils einer 1 beim zutreffenden Merkmal transformiert)
Die numerischen Werte werden skaliert, sodass sie nunmehr Werte im Bereich 0 und 1 annehmen. Anschließend werden verschiedene Algorithmen mit dem Trainingsdatensatz trainiert, Prognosen mit den Inputwerten des Testdatensatzes erzeugt und verschiedene Klassifikationsmetriken berechnet. Um zu evaluieren, ob die Modelle brauchbar sind, vergleichen wir sie mit 3 Dummy Benchmark Modellen: a. Alle Kaufen, b. keiner Kauft und einem Zufallsmodell.
Da unser Datensatz ein Klassenungleichgewicht vorweist (30 % Käufer im Test) messen wir die Performance mit dem sogenannten ROC_AUC Score
(https://de.wikipedia.org/wiki/ROC-Kurve).
Diese misst die Effizienz in Abhängigkeit der Fehlerrate. Ein Wert nahe 50% deutet auf ein Zufallsmodell hin, ein Wert bei 100 % ist perfekt (und zu gut um wahr zu sein). Werte zwischen 70 % und 80 % sind akzeptabel und Werte zwischen 80 % und 90 % deuten auf exzellente Unterscheidungsfähigkeit des Models hin.
WICHTIG!
Es soll hier auch demonstriert werden, dass es in echten Anwendungen sehr leicht zu einer sogenannten Data Leakage kommen kann. Es muss immer gewährleistet sein, dass nur jene Informationen als Input dienen, die zum Zeitpunkt einer Prognose auch tatsächlich vorhanden sind.
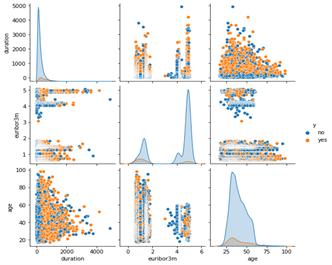
Abbildung 1: Beispiel für Visual Analytics im Bank Marketing Datensatz. Orange Datenpunkte sind Abschlüsse, blaue Punkte keine Abschlüsse.
Wenn man mithilfe von Datenvisualisierungen die Werte der einzelnen Merkmale darstellt bzw. Paare von Variablen darstellt und jene Kunden, welche nicht abgeschlossen haben, blau einfärbt bzw. jene die abgeschlossen haben orange einfärbt, dann sieht man sofort, dass beide Klassen zum Großteil übereinander liegen. Das ist problematisch, wenn keine Algorithmen zur Verfügung stehen, weil es ist anhand der Merkmalswerte für einen Business Analysten nur schwer möglich zu entscheiden, wie hoch die Wahrscheinlichkeit ist, dass ein gegebener Kunde abschließt.
Das Ergebnis:
Unsere Dummy Modelle haben alle Scores bei 49% - 51%, wie erwartet. Eine Logistische Regression erzielt 81,9 % und ein RandomForrest Classifier 82,5% und sind somit sehr gut. Wenn wir uns aber die Wichtigkeit der Input-Merkmale anschauen, dann sehen wir, dass das Merkmal „duration“ an 1. Stelle liegt. Duration zeigt die Zeit des Telefongespräches mit dem Kunden an und ist nach Durchführung der Kampagne bekannt. Zusätzlich korreliert dieses Merkmal mit der Klasse Nicht-Kauf, weil bei einer Gesprächsdauer von 0 auch kein Kauf erfolgt.
Daher darf dieses Merkmal gar nicht als Input verwendet werden. Wenn es entfernt und das Training mit den gleichen Modellen wiederholt wird, erhalten wir als bestes Modell ein neuronales Netzwerk mit 2 Schichten, welches einen Score von 73,1 Prozent erzielt. Das ist niedriger als zuvor, aber noch immer im akzeptablen Bereich und deutlich höher als der Zufall.
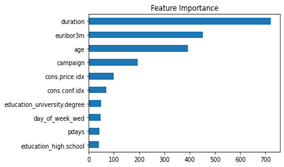
Abbildung 2: Feature Importance des Random Forrest mit allen Merkmalen (Top 10) werden gezeigt.
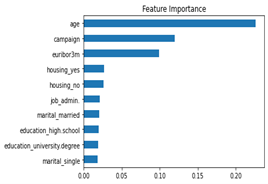
Abbildung 3: Feature Importance nach Entfernung der Duration und erneutem Training.